

Table of Links
Appendix
4.2 Baselines
We use two prior works, Ellis et al. [11] and CSGNet [28] as baseline methods.
CSGNet Sharma et al. [28] employed a convolutional and recurrent neural network to generate program statements from an input image. For a fair comparison, we re-implemented CSGNet using the same vision-language transformer architecture as our method, representing the modern autoregressive approach to code generation. We use rejection sampling, repeatedly generating programs until a match is found.
REPL Flow Ellis et al. [11] proposed a method to build programs one primitive at a time until all primitives have been placed. They also give a policy network access to a REPL, i.e., the ability to execute code and see outputs. Notably, this current image is rendered from the current partial program. As such, we require a custom partial compiler. This is straightforward for CSG2D since it is a compositional language. We simply render the shapes placed so far. For TinySVG, it is not immediately obvious how this partial compiler should be written. This is because the rendering happens bottom-up. Primitives get arranged, and those arrangements get arranged again (see Figure 1). Therefore, we only use this baseline method with CSG2D. Due to its similarities with Generative Flow Networks [3], we refer to our modified method as “REPL Flow”.
Test tasks For TinySVG we used a held-out test set of randomly generated expressions and their images. For the CSG2D task, we noticed that all methods were at ceiling performance on an indistribution held-out test set. In Ellis et al. [11], the authors created a harder test set with more objects. However, simply adding more objects in an environment like CSG2D resulted in simpler final scenes, since sampling a large object that subtracts a large part of the scene becomes more likely. Instead, to generate a hard test set, we filtered for images at the 95th percentile or more on incompressibility with the LZ4 [7, 37] compression algorithm.

All methods were trained with supervised learning and were not fine-tuned with reinforcement learning. All methods used the grammar-based constrained decoding method described in Section 3.4, which ensured syntactically correct outputs. While testing, we measured performance based on the number of compilations needed for a method to complete the task.
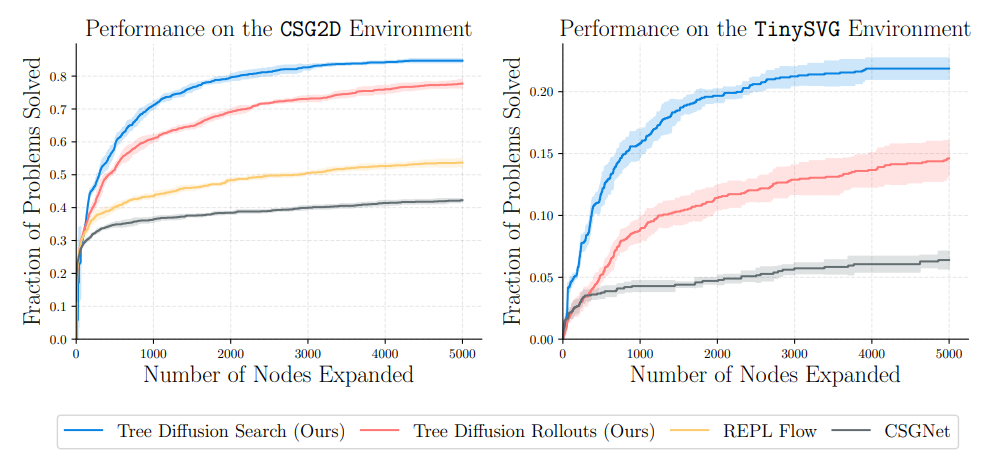
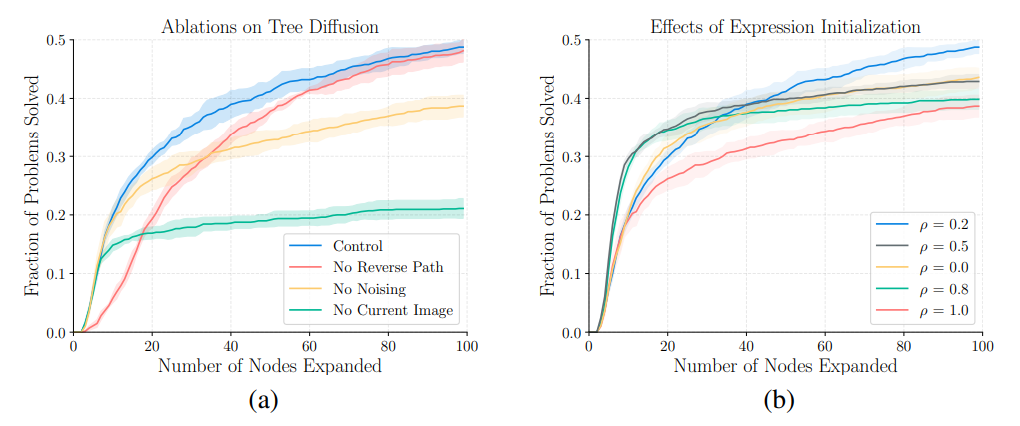
Figure 4 shows the performance of our method compared to the baseline methods. In both the CSG2D and TinySVG environments, our tree diffusion policy rollouts significantly outperform the policies of previous methods. Our policy combined with beam search further improves performance, solving problems with fewer calls to the renderer than all other methods. Figure 6 shows successful qualitative examples of our system alongside outputs of baseline methods. We note that our system can fix smaller issues that other methods miss. Figure 7 shows some examples of recovered programs from sketches in the CSG2D-Sketch language, showing how the observation model does not necessarily need to be a deterministic rendering; it can also consist of stochastic hand-drawn images.
Authors:
(1) Shreyas Kapur, University of California, Berkeley ([email protected]);
(2) Erik Jenner, University of California, Berkeley ([email protected]);
(3) Stuart Russell, University of California, Berkeley ([email protected]).
This paper is